Abstract
The attention mechanism has revolutionized deep learning research across many disciplines starting from NLP and expanding to vision, speech, and more. Different from other mechanisms, the elegant and general attention mechanism is easily adaptable and eliminates modality-specific inductive biases. As attention becomes increasingly popular, it is crucial to develop tools to allow researchers to understand and explain the inner workings of the mechanism to facilitate better and more responsible use of it. This tutorial focuses on understanding and interpreting attention in the vision and the multi-modal setting. We present state-of-the-art research on representation probing, interpretability, and attention-based semantic guidance, alongside hands-on demos to facilitate interactivity. Additionally, we discuss open questions arising from recent works and future research directions.
Tutorial Outline
The following is an outline of the topics we will cover in the tutorial. A detailed description can be found in this document.
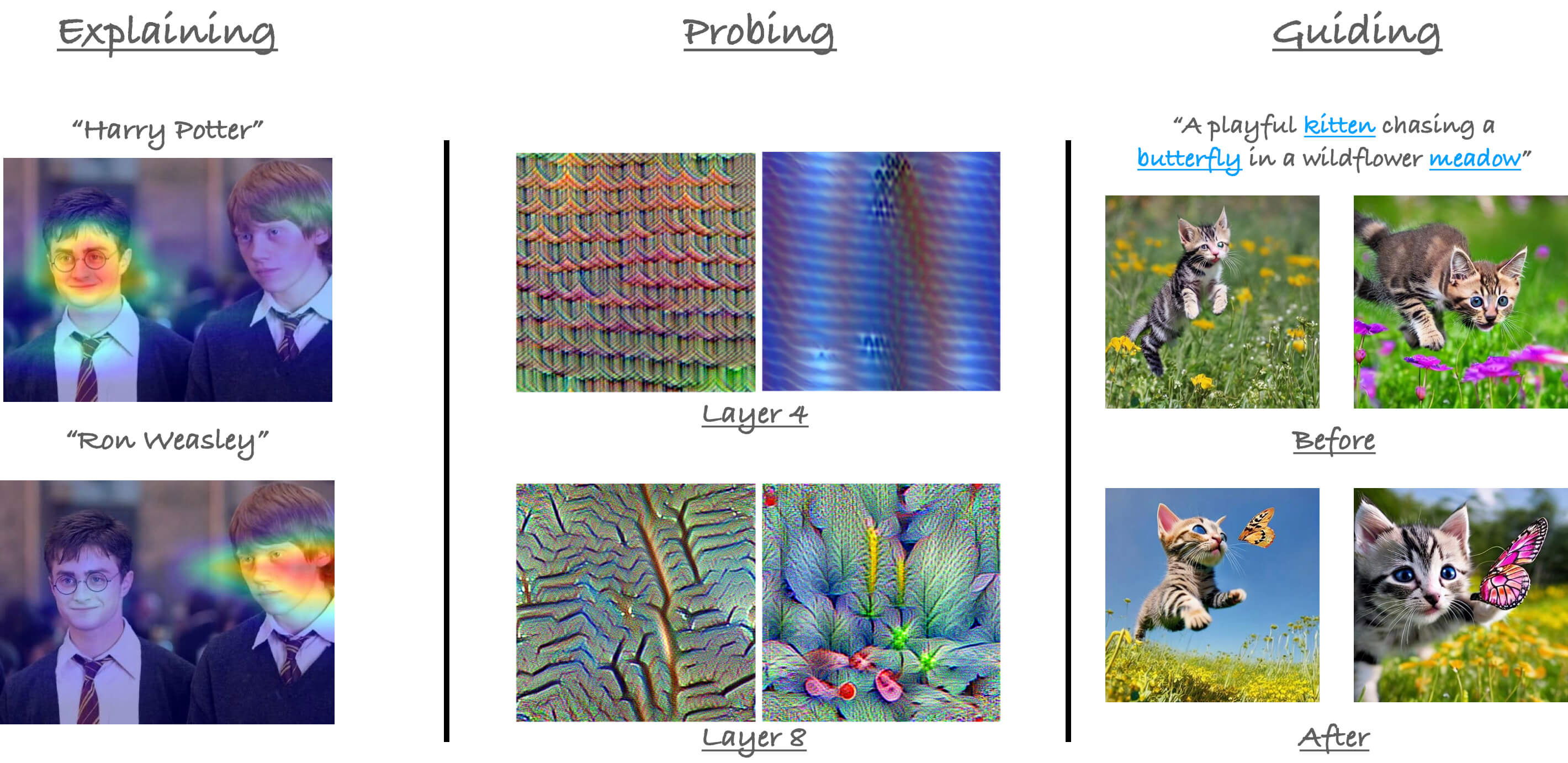
Interpreting Attention
- Brief history of interpretability for DNNs
- Attention vs. Convolutions
- Using attention as an explanation
Probing Attention
- Depth and breadth of attention layers
- Representational similarities between CNNs and Transformers
-
Probing cross-attention
Leveraging Attention as Explanation
- New! Ron Mokady will share his seminal research on employing attention for text-based image editing. You can find his slides here.
- Attention-based semantic guidance
Tutorial Logistics
Our tutorial will be conducted in a hybrid manner on June 18, 2022 from 9 AM onwards. We aim to complete our tutorial by 12:00 PM (Canada time). Due the VISA issues, Sayak won't be able to present in person. So, he will be joining and presenting virtually. Our guest speaker Ron will also be presenting virtually. However, Hila will be presenting in person.
- For in-person attendees: Our tutorial will be presented at the Vancouver Convention Center West 211.
- For virtual attendees: Please see the virtual site, where you can find the homepage of our tutorial. All the (registered) participants (both in-person and virtual) of CVPR will have access to a Zoom link to join the tutorial live and ask questions to the speakers via RocketChat.
References
[1] Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers, Chefer et al.
[2] Do Vision Transformers See Like Convolutional Neural Networks?, Raghu et al.
[3] What do Vision Transformers Learn? A Visual Exploration, Ghiasi et al.
[4] Quantifying Attention Flow in Transformers, Abnar et al.
[5] Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models, Chefer et al.
[6] Prompt-to-Prompt Image Editing with Cross-Attention Control, Hertz et al.
[7] NULL-text Inversion for Editing Real Images using Guided Diffusion Models, Mokady et al.